換臉效果不夠真實,能讓你看出破綻?看看北大和微軟的研究者如何生成更加真實的換臉效果,如何解決遮擋、光線等各種問題。
換臉是非常吸引人的一種應用,開發者可以用 VAE 或 GAN 做出非常炫酷的效果。一般而言,換臉會將 A 臉特征換到 B 臉上,同時保留 B 臉的神情或動態。像 FaceSwap 這樣開源項目已經能生成非常真實的假臉視頻,不過仔細看看仍然會發現有的地方存在模糊,有的地方轉換不太自然。
那么怎樣才能生成轉換更自然,效果更真實的換臉視頻?這就是這篇論文的研究目的,研究者新模型不僅感官上更真實,同時還保留了比其它前沿方法更多的個人特征。
下面我們先看看效果:

研究者同時從網絡上下載人臉圖像以展示 FaceShifter 的強大能力。如圖 11 所示,新方法可以處理不同情況下(如夸張的動作、非常見光照以及極其復雜的面部遮擋)的人臉圖像。

研究者此次提出了一種新型的兩段式框架——FaceShifter。這個框架可以完成高保真的換臉過程,在面部有遮擋時依然可以很好地工作。不像那些只利用有限信息就完成換臉任務的框架,該框架中的第一部分就自適應地整合了目標圖像的所有屬性以生成高保真的換臉圖片。
此外,研究者提出了一種新型的屬性編碼器以提取人臉圖像的多級屬性,同時提出了一種基于 Adaptive Attentional Denormalization (AAD) 的新型生成器,自適應地整合人臉合成時所需的特征和屬性。
為了解決臉部遮擋的問題,研究者在框架中加入了第二部分——Heuristic Error Acknowledging Refinement Network (HEAR-Net)。這個網絡通過自監督的方式,在沒有人工標注的情況下實現異常區域的修復。
下面,讓我們看看這種高逼真度的換臉到底是怎么樣的。
論文:FaceShifter: Towards High Fidelity And Occlusion Aware Face Swapping

論文地址:https://arxiv.org/pdf/1912.13457.pdf
換臉的缺陷與改進
換臉技術就是將目標圖像中人臉的面部特征替換為源圖像人臉的對應部分,同時還要保留一些如頭部動作、臉部表情、光線、背景等基本屬性。由于這一技術在電影合成、電腦游戲以及隱私保護等方面有很廣泛的應用前景,這一技術已經廣泛引起了視覺和圖像領域的關注。
最近,基于 GAN 的一些工作已經取得了很不錯的結果。但是,如何生成真實且保真的圖像依舊是個很大的難題。
因此我們這項工作的重點之一就是提高換臉后圖像的保真度。為了讓結果在感官上更具吸引力,如何讓合成的換臉圖像無縫融入新臉,同時保持原有姿勢表情,這就是我們要研究的重點。也就是說,換臉圖像的渲染應當忠于目標圖像的光線(方向,強度,顏色等),被交換的臉也應該跟目標圖像有相同的分辨率。
這些都不是僅僅 Alpha 或是 Poisson 混合能夠解決的,我們真正需要的是讓換臉過程可以自適應地繼承目標圖像完整屬性信息,這樣目標圖像的屬性(亮度、分辨率等)就可以讓換臉后的圖像變得更加真實。
然而,以前的方法要么忽略了這一需求,要么就是無法自適應或者完整地集成這些信息。具體來說,以往的許多方法僅利用目標圖像的姿態和表情來指導換臉過程,然后利用目標人臉 Mask 將人臉混合到目標圖像中。這一過程容易產生一些缺陷,因為:
1)在合成換臉圖像時,除了姿態和表情外,對目標圖像的了解很少,很難保證場景光照或圖像分辨率等目標屬性不發生變化;2)這樣的混合將丟棄位于目標 Mask 外部的源面部特征。
因此,這些方法不能保持源標識的面形,我們在圖 2 中展示了一些典型的失敗案例。
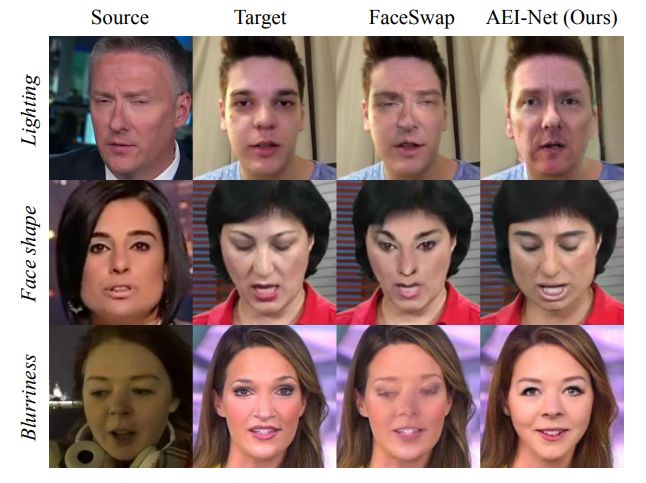
圖 2:之前方法在 FaceForensics++數據集上的失敗案例
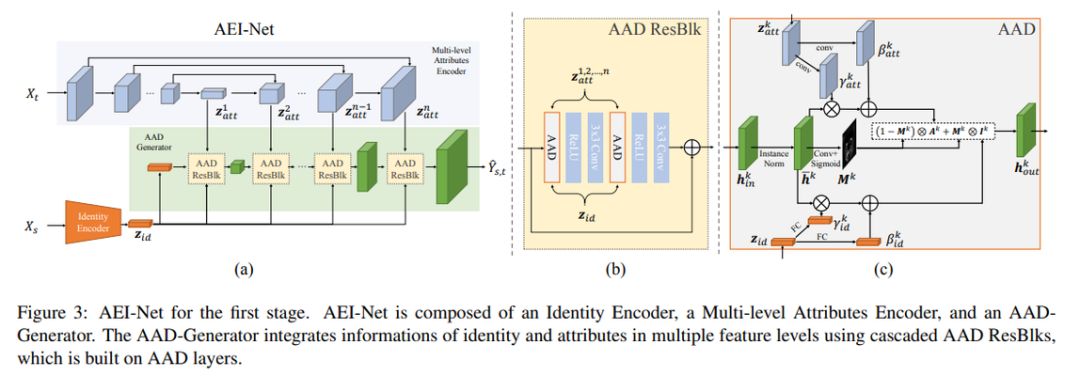
為了實現高保真的人臉交換結果,在框架的第一階段,我們設計了一個基于 GAN 的網絡以對目標屬性進行徹底的自適應集成,并稱之為自適應嵌入集成網絡(Adaptive Embedding Integration Network,AEI-Net)。我們對網絡結構做了兩個改進:
1)我們提出了一種新的多級屬性編碼器,用于提取各種空間分辨率下的目標屬性,而不是像 RSGAN[28] 和 IPGAN[5] 那樣將其壓縮成單個向量;
2)提出了一種有 Adaptive Attentional Denormalization(AAD) 層的新型生成器器,該發生器自適應地學習了在何處集成屬性以及特征的嵌入。與 RSGAN[28]、FSNet[27] 和 IPGAN[5] 的單級集成相比,這種自適應集成為結果帶來了相當大的改進。
通過這兩個改進,我們提出的 AEI-Net 可以解決圖 2 中光照不一致和人臉形狀不一致的問題。
此外,處理面部的遮擋一直是換臉的挑戰。Nirkin 等人的方法中對人臉進行分割并訓練以使其能感知到臉部的遮擋部分,我們的方法可以以一種自監督的方式學習恢復人臉異常區域,而且不需要任何人工標注。我們觀察到,當把同一張人臉圖像同時作為目標圖像和源圖像,并輸入到一個訓練良好的 AEI 網絡時,重建的人臉圖像跟輸入圖像有多處改變,這些改變所在的位置基本上就是臉部遮擋的區域。
因此,我們提出了一種新的 Heuristic Error Acknowledging Refinement Network (HEAR-Net),在這種重構誤差的指導下進一步精化結果。重要的是,這個方法不止是能修正臉部遮擋,它還可以識別很多其他的異常類型,如眼鏡、陰影和反射效應。
我們提出的兩段式換臉框架 FaceShifter 與場景無關。一旦訓練完成,該模型就可以應用于任何新的人臉對,而不需要像 DeepFakes 和 Korshunova 等人的 [21] 那樣找特定的受試者訓練。實驗結果表明,與其他先進的方法相比,我們的方法獲得的結果更真實、更可靠。
FaceShifter 模型什么樣
我們的方法需要輸入兩張圖像——提供人臉特征的源圖像 X_s 以及提供動作、表情、光線、背景等屬性的目標圖像 X_t。最終的換臉圖像是通過兩段式框架 FaceShifter 生成的。在第一階段中, 我們的 AEINet 自適應地基于集成信息生成了一個高保真的換臉結果
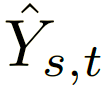
。在第二階段,我們使用 Heuristic Error Acknowledging Network (HEARNet) 來處理面部遮擋,并對結果進行改進,最后的結果用
表示。
自適應嵌入集成網絡(Adaptive Embedding Integration Network)
在第一階段,我們希望生成一個高保真(擁有源圖像 X_s 特征,且保留目標圖像 X_t 動作等屬性)的人臉圖像
。為了達到這一目標,我們的方法包含三個模塊:
i)從源圖像中抽取特征的特征編碼器 z_id(X_s);
ii)從目標圖像 X_t 抽取屬性的多級屬性編碼器 z_att(X_t);
iii)基于 Adaptive Attentional Denormalization (AAD) 生成換臉圖像的生成器。
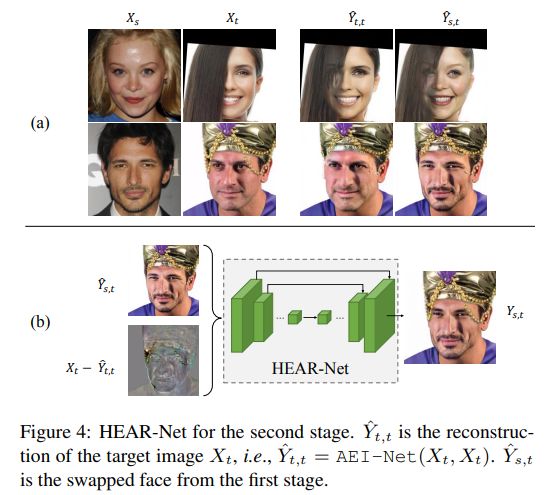
啟發式誤差修正網絡(Heuristic Error Acknowledging Refinement Network)
盡管 AEINet 第一階段的換臉結果
已經能很好的獲取目標圖像的動作、表情、光照等屬性,但是當目標臉部圖像 Xt 中對臉部有遮擋時,這種遮擋就很難被繼承下來。為了解決這個問題,過去的一些方法 [30,29] 加入了一個新的臉部分割網絡。這個網絡的訓練數據需要進行大量標注(哪一部分有遮擋),而且這種有監督方式可能很難識別出未知的遮擋方式。
對于面部遮擋問題,我們提出了一種啟發式的方法。如圖 4(a) 所示,當目標圖像中的臉被遮擋時(頭發或是帽子上的鐵鏈),有一部分遮擋會在換臉過程中小時。同時,我們發現,就算我們把同一張圖同時作為源圖像和目標圖像輸入給訓練好的 AEI-Net,這種遮擋還是會在重建的圖像中消失。此時這種輸出與輸入的誤差,就可以作為我們定位面部遮擋的依據,我們把這種依據叫做輸入圖像的啟發式錯誤,因為這個誤差啟發性的表征了異常發生的位置。
實驗效果怎么樣
與過去方法的比較
1. 定性對比
圖 5 展示了我們在 FaceForensics++數據集上與 FaceSwap [2], Nirkin et al. [30], DeepFakes [1] 和 IPGAN [5] 的比較。
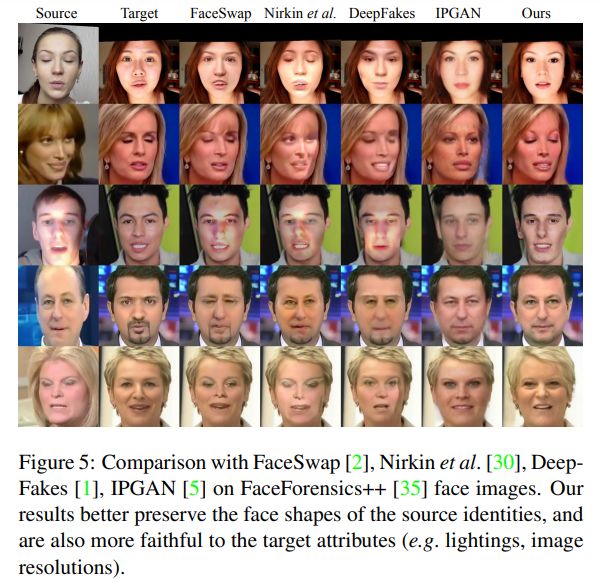
圖 6 則展示了我們的方法與最新方法 FSGAN 的對比。
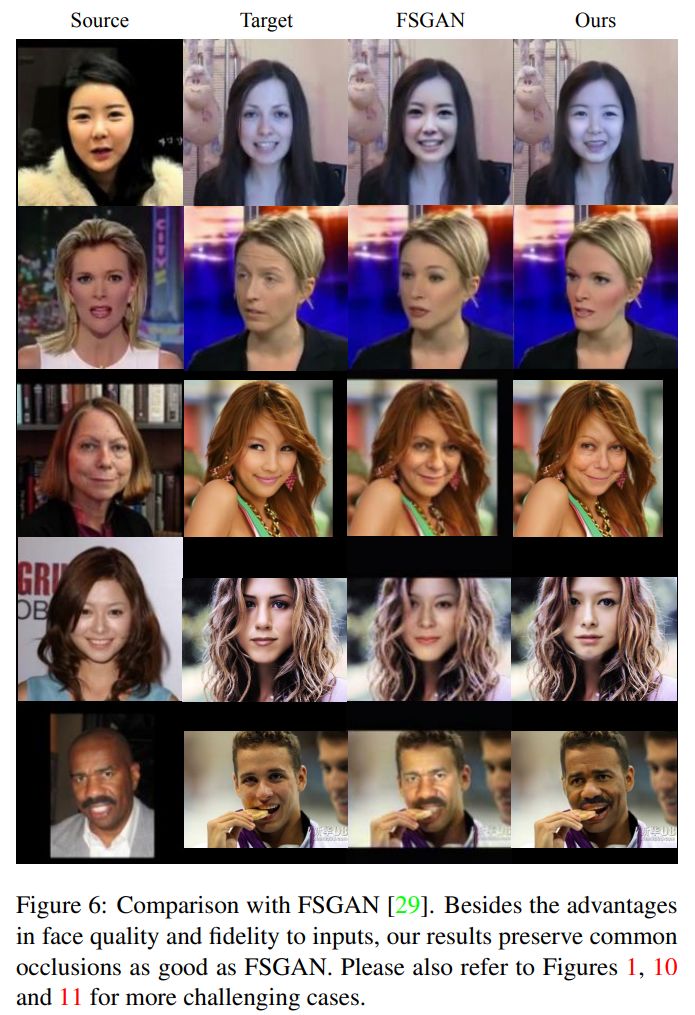
由于 FaceSwap [2], Nirkin et al. [30], DeepFakes [1] 和 IPGAN [5] 的策略都是先生成臉部區域圖像,然后將其嵌入到目標臉中,我們可以從比較中明顯的看出這些方法的嵌入誤差。
這些方法生成的所有人臉與其目標人臉有著完全相同的人臉輪廓,而且源人臉的形狀也被忽略了(圖 5 第 1-4 行及圖 6 第 1-2 行)。除此之外, 他們的研究結果一定程度上忽略了目標圖像的一些重要信息,如光照(圖 5 第 3 行,圖 6 第 3 - 5 行),圖像分辨率(圖 5 第 2 行和第 4 行)。由于 IPGAN[5] 的矩陣只描述了單一級別的屬性,因此其所有樣本都顯示出了分辯率下降的問題。同時,IPGAN 也不能很好地保存目標面部的表情,如閉上的眼睛(圖 5 第 2 行)。
我們的方法很好地解決了所有這些問題,實現了更高的保真度——保留了源人臉(而非過去的目標人臉)的臉部輪廓,且保證了目標圖像(而非過去的源人臉)的光線與圖像分辨率。我們的方法在處理面部遮擋問題上的表現甚至可以超過 FSGAN [29]。
2. 定量對比
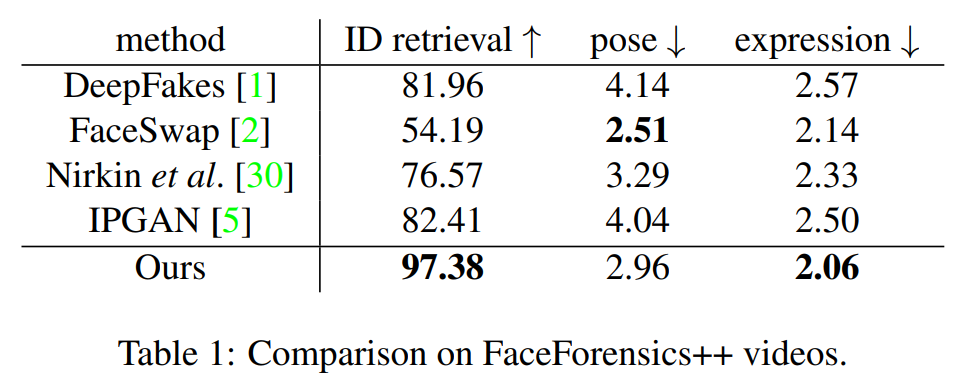
我們使用不同的人臉識別模型 [41] 提取特征向量,并采用余弦相似度來度量特征差距。我們從 FaceForensics++的原始視頻中為每個測試集中的換臉結果匹配了一張最接近的臉,以檢查這張臉是否屬于正確的源視頻。表 1 中的 ID 就是使用該方法獲得的平均準確率,這個方法可以用來測試特征保留能力。我們提出的框架獲得了更高的 ID 分數,且檢索范圍很大。
3. 人為評估
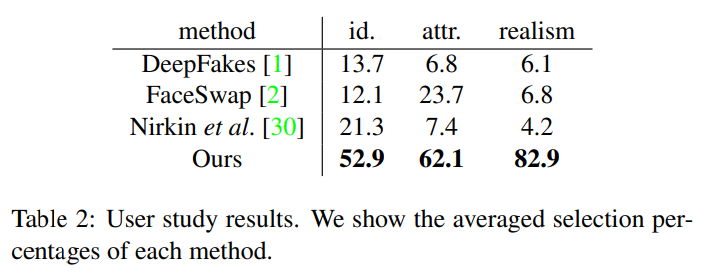
我們做了三次用戶調研,以評測本模型的表現。我們讓用戶從以下選項中選擇:i)與源臉最相似的圖像;ii)與目標圖像有最相似動作、表情、光照的圖像;iii)最真實的圖像。
表 2 展示了每個方法在其研究中的平均被選取率。這個結果現實我們的模型在大范圍上超過了其余三個模型。
框架分析

圖 7:AEI-Net 與三個 baseline 模型的對比結果

圖 8:在不同特征級上,AAD 層中基于注意力機制的 Mask Mk 可視化。

圖 9:基于屬性嵌入的查詢結果
圖 10:第二階段中修正結果展示了 HEAR-Net 在各種誤差(遮擋、反光、動作微移、顏色)上的強大能力。
來源 | 機器之心