成員動(dòng)態(tài)
PhoneBit: 基于手機(jī) GPU 的高能效二值神經(jīng)網(wǎng)絡(luò)加速引擎開源項(xiàng)目發(fā)布
在過去的幾年里,深度神經(jīng)網(wǎng)絡(luò)(DNN)已經(jīng)在計(jì)算機(jī)視覺和其他領(lǐng)域取得了巨大的進(jìn)展。然而,由于深度神經(jīng)網(wǎng)絡(luò)較高的計(jì)算復(fù)雜度,以及移動(dòng)設(shè)備性能和功率限制,導(dǎo)致深度神經(jīng)網(wǎng)絡(luò)在移動(dòng)設(shè)備上部署仍然具有挑戰(zhàn)性。二值神經(jīng)網(wǎng)絡(luò)(Binary Neural Networks)是一種特殊的神經(jīng)網(wǎng)絡(luò),它將網(wǎng)絡(luò)的權(quán)重和中間特征壓縮為 1 個(gè)比特位,通過使用位運(yùn)算替代傳統(tǒng)的浮點(diǎn)運(yùn)算來實(shí)現(xiàn)模型的壓縮與加速。現(xiàn)有的大多數(shù)神經(jīng)網(wǎng)絡(luò)計(jì)算框架,如MXNet、Caffe、TensorFlow等,它們大多為浮點(diǎn)計(jì)算框架,并只針對(duì)桌面平臺(tái)的獨(dú)立GPU優(yōu)化。相比桌面與服務(wù)器獨(dú)立GPU,移動(dòng)端GPU往往與CPU合并在一塊芯片上作為SoC的一部分,同時(shí)存在著功率小、可分配資源少、帶寬低等限制,這使得在移動(dòng)端GPU上進(jìn)行并行計(jì)算的優(yōu)化與獨(dú)立GPU有很大的不同。而在移動(dòng)設(shè)備上,大多數(shù)輕量級(jí)框架如TensorFlow Lite,CNNdroid,Core ML,Caffe2等,它們大多支持浮點(diǎn)與8bit量化,并不支持BNN,同時(shí)存在一定兼容性問題,如TensorFlow Lite對(duì)移動(dòng)GPU的支持并不完善。2019年8月,京東AI開源了第一個(gè)基于ARM CPU的高度優(yōu)化的BNN前向傳播計(jì)算框架daBNN,但是daBNN使用CPU計(jì)算使得daBNN和其他使用CPU計(jì)算的框架一樣,仍然具有在運(yùn)算時(shí)發(fā)熱大、消耗電量快等缺點(diǎn)。因此,使用移動(dòng)GPU對(duì)BNN進(jìn)行推理計(jì)算優(yōu)化仍然是一個(gè)空白。
中山大學(xué)無人系統(tǒng)研究所陳剛副教授和黃凱教授聯(lián)合鵬城實(shí)驗(yàn)室發(fā)表在DATE 2020的論文 《PhoneBit: Efficient GPU-Accelerated Binary Neural Network Inference Engine for Mobile Phones》提出了業(yè)界首個(gè)基于手機(jī) GPU 的高能效二值神經(jīng)網(wǎng)絡(luò)加速引擎,針對(duì)移動(dòng)端GPU進(jìn)行高度優(yōu)化。PhoneBit框架在進(jìn)行二值神經(jīng)網(wǎng)絡(luò)推理的同時(shí),可大幅提升推理速度,降低計(jì)算消耗的電量以及帶來更高的能耗比。目前,PhoneBit框架已在鵬城匯智開源代碼托管平臺(tái)上正式發(fā)布(地址:https://code.ihub.org.cn/projects/915)。
如下圖所示,PhoneBit框架加載一個(gè)在其他框架上訓(xùn)練好的模型,模型經(jīng)過轉(zhuǎn)換工具的轉(zhuǎn)換后,上傳至移動(dòng)設(shè)備,只需要簡(jiǎn)單幾步即可完成模型的部署。
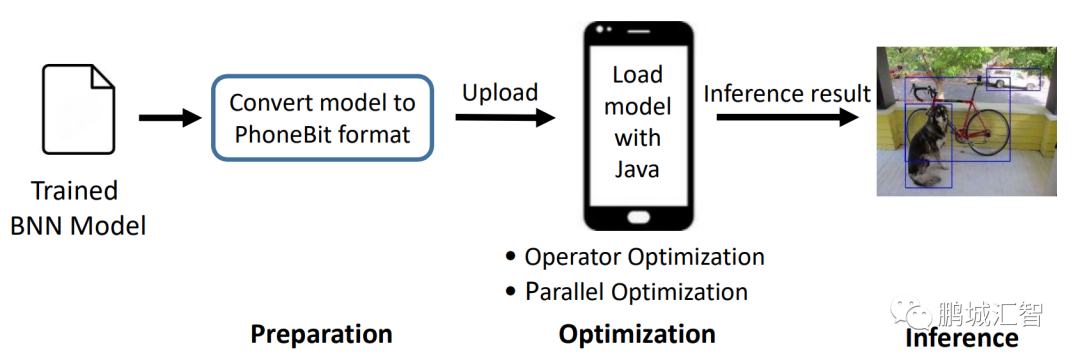
PhoneBit框架于移動(dòng)端快捷部署B(yǎng)NN模型
同時(shí),PhoneBit框架為使用者提供了多項(xiàng)支持:
1) 提供了對(duì)多種常用神經(jīng)網(wǎng)絡(luò)層的支持,例如add,convolution,max pooling,average pooling,BN,dense,softmax等層,同時(shí)支持shortcut結(jié)構(gòu)并有對(duì)應(yīng)的優(yōu)化,理論上可適應(yīng)大多數(shù)網(wǎng)絡(luò)結(jié)構(gòu)。
2) 支持混合精度,支持32位浮點(diǎn),16位浮點(diǎn),int8整數(shù),二值化等計(jì)算方式。
3)提供了模型轉(zhuǎn)換工具,支持從ONNX(Open Neural Network Exchange)模型轉(zhuǎn)換至本框架專用模型,在轉(zhuǎn)換模型的同時(shí)進(jìn)行針對(duì)BNN的模型壓縮與半精度浮點(diǎn)格式的轉(zhuǎn)換,。
4) 考慮到Android應(yīng)用大多采用Java編寫,本框架提供了方便的Java API支持,使用者只需要簡(jiǎn)單的調(diào)用幾行Java代碼,即可自動(dòng)實(shí)現(xiàn)模型的GPU推理計(jì)算。

使用框架進(jìn)行BNN模型加載與推理
在BNN前向計(jì)算過程中,由于輸入特征與權(quán)重只包含1與-1兩種值,因此一個(gè)輸入特征和權(quán)重可以只用1個(gè)二進(jìn)制位來表示,而通常的輸入特征與權(quán)重是浮點(diǎn)數(shù),一個(gè)浮點(diǎn)數(shù)需要使用32個(gè)二進(jìn)制位來表示,二者相差32倍,因此,BNN相比通常的浮點(diǎn)DNN,理論上可以將模型縮小32倍,同時(shí)計(jì)算上提升32倍的速度。在計(jì)算卷積層時(shí),有大量的向量點(diǎn)乘操作。在BNN中,通過數(shù)學(xué)推導(dǎo),傳統(tǒng)的浮點(diǎn)向量點(diǎn)乘操作可以被以下公式替代:
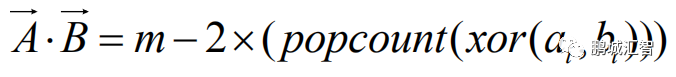 其中,
其中,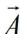 與
與 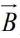 是由浮點(diǎn)向量經(jīng)過壓縮后的二值向量,
是由浮點(diǎn)向量經(jīng)過壓縮后的二值向量,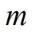 是向量的長度,
是向量的長度,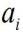 與
與 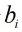 分別是、 中每個(gè)比特位。因此,在BNN中的卷積計(jì)算時(shí)采用上述公式,就能完成使用1位二進(jìn)制位計(jì)算代替通常的32位計(jì)算,極大的減小了傳輸?shù)臄?shù)據(jù)量與計(jì)算量。同時(shí),在BNN計(jì)算中將卷積層、Batch-Normalization(BN)層、二值化層(將浮點(diǎn)數(shù)據(jù)變?yōu)?與-1的層)整合,通過層與層之間的整合,層之間額外的數(shù)據(jù)傳輸以及計(jì)算量得到大幅度降低,從而節(jié)省時(shí)間。
分別是、 中每個(gè)比特位。因此,在BNN中的卷積計(jì)算時(shí)采用上述公式,就能完成使用1位二進(jìn)制位計(jì)算代替通常的32位計(jì)算,極大的減小了傳輸?shù)臄?shù)據(jù)量與計(jì)算量。同時(shí),在BNN計(jì)算中將卷積層、Batch-Normalization(BN)層、二值化層(將浮點(diǎn)數(shù)據(jù)變?yōu)?與-1的層)整合,通過層與層之間的整合,層之間額外的數(shù)據(jù)傳輸以及計(jì)算量得到大幅度降低,從而節(jié)省時(shí)間。
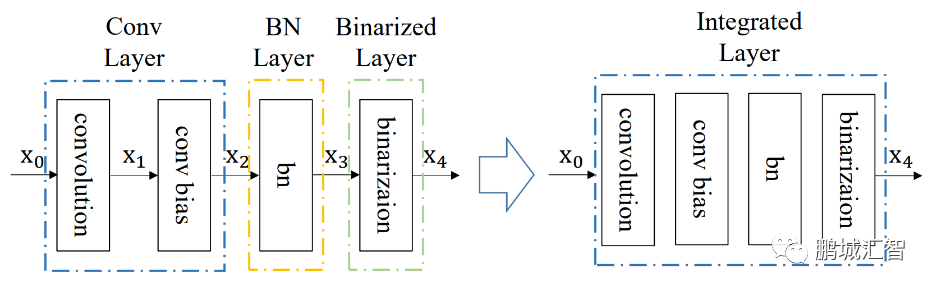
同時(shí),針對(duì)移動(dòng)GPU的體系結(jié)構(gòu),PhoneBit框架采用了向量化訪存與計(jì)算、合并內(nèi)存訪問、隱藏訪存延遲、合理安排計(jì)算量負(fù)載、避免邏輯分支的判斷等計(jì)算優(yōu)化方法。相比于矢量方式1次指令只能讀取1個(gè)數(shù)據(jù),向量化方式讀寫使得計(jì)算時(shí)GPU可以只使用1次指令即可讀取若干個(gè)數(shù)據(jù)如4個(gè)、8個(gè)甚至16個(gè),達(dá)到高效利用內(nèi)存帶寬的效果;合并內(nèi)存訪問則是將GPU中同一批計(jì)算單元安排處理內(nèi)存上連續(xù)的數(shù)據(jù),這樣訪存時(shí)不需要間隔訪問,達(dá)到最大的讀寫率;隱藏訪存延遲則通過安排GPU中一批計(jì)算單元計(jì)算時(shí),另一批待計(jì)算的單元同時(shí)讀取數(shù)據(jù),避免相互等待;合理安排計(jì)算量負(fù)載則是根據(jù)計(jì)算規(guī)模的不同,調(diào)整GPU同一批計(jì)算單元進(jìn)行計(jì)算的數(shù)據(jù)量,使之不會(huì)因?yàn)橛?jì)算數(shù)據(jù)量過少而造成浪費(fèi),也不會(huì)因?yàn)閿?shù)據(jù)量過多造成擁塞。避免邏輯分支則是盡可能讓GPU中同一批計(jì)算單元執(zhí)行相同的條件分支代碼,節(jié)省執(zhí)行時(shí)間。通過以上優(yōu)化方法,PhoneBit框架速度比較如下:
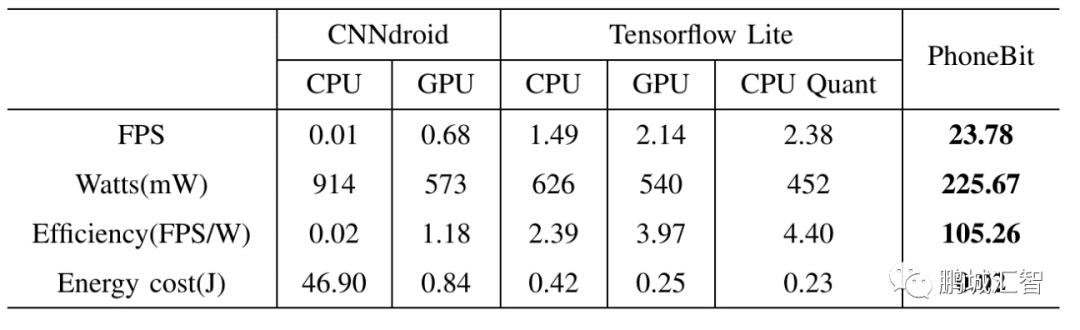
于高通驍龍820平臺(tái)運(yùn)行YOLOv2 Tiny網(wǎng)絡(luò)與現(xiàn)有主流浮點(diǎn)DNN框架對(duì)比
在高通驍龍820平臺(tái),運(yùn)行YOLOv2 Tiny網(wǎng)絡(luò),相比CNNdroid(一個(gè)基于Android RenderScript的浮點(diǎn)神經(jīng)網(wǎng)絡(luò)前向傳播框架),PhoneBit框架實(shí)現(xiàn)了1218-2378倍的速度提升,2.54-4.05倍更低的功率以及89-5263倍更高的能效比。相比TensorFlow Lite(谷歌針對(duì)移動(dòng)設(shè)備提出的輕量級(jí)神經(jīng)網(wǎng)絡(luò)前向傳播框架,支持浮點(diǎn)與8bit量化模式),PhoneBit框架實(shí)現(xiàn)了10-15.6倍的速度提升,2-2.77倍更低的功率以及23.9-44倍更高的能效比。

于高通驍龍820平臺(tái)運(yùn)行Bi-Real Net 18網(wǎng)絡(luò)與現(xiàn)有基于ARM的BNN框架對(duì)比
在高通驍龍820平臺(tái),運(yùn)行Bi-Real Net 18網(wǎng)絡(luò),相比daBNN(一個(gè)最新的基于ARM高度優(yōu)化的二值神經(jīng)網(wǎng)絡(luò)框架),PhoneBit框架實(shí)現(xiàn)了2.6倍的速度提升,2.62倍更低的功率以及6.8倍更高的能效比。
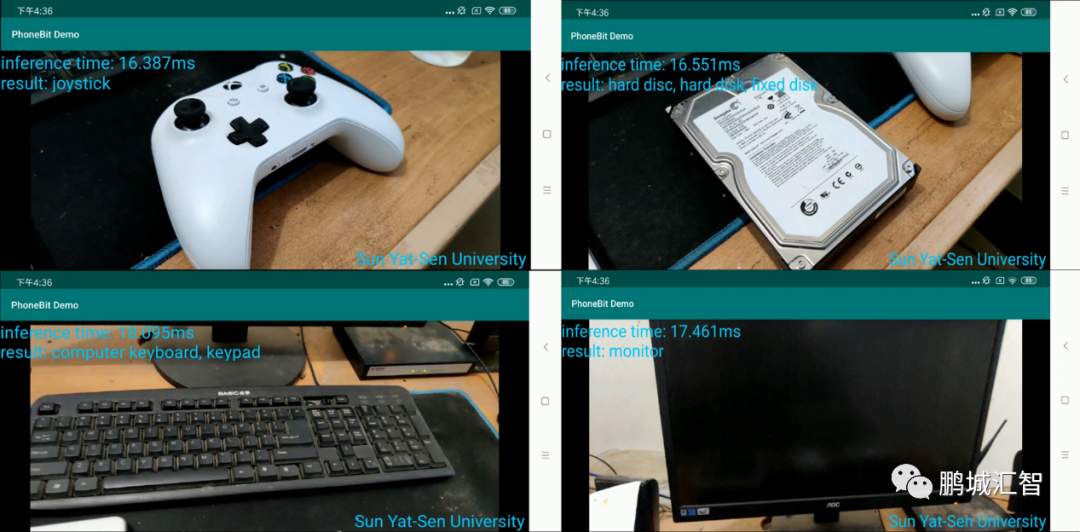
PhoneBit框架使用Bi-Real Net 18網(wǎng)絡(luò)對(duì)物品進(jìn)行分類
目前,PhoneBit框架項(xiàng)目仍在不斷快速迭代進(jìn)化,框架整體性能亦在不斷提升中,希望能夠以此項(xiàng)目為相關(guān)領(lǐng)域的科研工作者、開發(fā)者們提供一個(gè)穩(wěn)定易用、高效便捷的輕量化神經(jīng)網(wǎng)絡(luò)加速引擎。同時(shí),也期望能有更多志同道合的朋友加入項(xiàng)目組,共同開發(fā)、優(yōu)化本項(xiàng)目,為PhoneBit框架的發(fā)展出一份力。
中山大學(xué)無人系統(tǒng)研究所陳剛副教授和黃凱教授聯(lián)合鵬城實(shí)驗(yàn)室發(fā)表在DATE 2020的論文 《PhoneBit: Efficient GPU-Accelerated Binary Neural Network Inference Engine for Mobile Phones》提出了業(yè)界首個(gè)基于手機(jī) GPU 的高能效二值神經(jīng)網(wǎng)絡(luò)加速引擎,針對(duì)移動(dòng)端GPU進(jìn)行高度優(yōu)化。PhoneBit框架在進(jìn)行二值神經(jīng)網(wǎng)絡(luò)推理的同時(shí),可大幅提升推理速度,降低計(jì)算消耗的電量以及帶來更高的能耗比。目前,PhoneBit框架已在鵬城匯智開源代碼托管平臺(tái)上正式發(fā)布(地址:https://code.ihub.org.cn/projects/915)。
PhoneBit框架及其優(yōu)化簡(jiǎn)介
如下圖所示,PhoneBit框架加載一個(gè)在其他框架上訓(xùn)練好的模型,模型經(jīng)過轉(zhuǎn)換工具的轉(zhuǎn)換后,上傳至移動(dòng)設(shè)備,只需要簡(jiǎn)單幾步即可完成模型的部署。
PhoneBit框架于移動(dòng)端快捷部署B(yǎng)NN模型
同時(shí),PhoneBit框架為使用者提供了多項(xiàng)支持:
1) 提供了對(duì)多種常用神經(jīng)網(wǎng)絡(luò)層的支持,例如add,convolution,max pooling,average pooling,BN,dense,softmax等層,同時(shí)支持shortcut結(jié)構(gòu)并有對(duì)應(yīng)的優(yōu)化,理論上可適應(yīng)大多數(shù)網(wǎng)絡(luò)結(jié)構(gòu)。
2) 支持混合精度,支持32位浮點(diǎn),16位浮點(diǎn),int8整數(shù),二值化等計(jì)算方式。
3)提供了模型轉(zhuǎn)換工具,支持從ONNX(Open Neural Network Exchange)模型轉(zhuǎn)換至本框架專用模型,在轉(zhuǎn)換模型的同時(shí)進(jìn)行針對(duì)BNN的模型壓縮與半精度浮點(diǎn)格式的轉(zhuǎn)換,。
4) 考慮到Android應(yīng)用大多采用Java編寫,本框架提供了方便的Java API支持,使用者只需要簡(jiǎn)單的調(diào)用幾行Java代碼,即可自動(dòng)實(shí)現(xiàn)模型的GPU推理計(jì)算。
使用框架進(jìn)行BNN模型加載與推理
在BNN前向計(jì)算過程中,由于輸入特征與權(quán)重只包含1與-1兩種值,因此一個(gè)輸入特征和權(quán)重可以只用1個(gè)二進(jìn)制位來表示,而通常的輸入特征與權(quán)重是浮點(diǎn)數(shù),一個(gè)浮點(diǎn)數(shù)需要使用32個(gè)二進(jìn)制位來表示,二者相差32倍,因此,BNN相比通常的浮點(diǎn)DNN,理論上可以將模型縮小32倍,同時(shí)計(jì)算上提升32倍的速度。在計(jì)算卷積層時(shí),有大量的向量點(diǎn)乘操作。在BNN中,通過數(shù)學(xué)推導(dǎo),傳統(tǒng)的浮點(diǎn)向量點(diǎn)乘操作可以被以下公式替代:
與 是由浮點(diǎn)向量經(jīng)過壓縮后的二值向量,是向量的長度, 與 分別是、 中每個(gè)比特位。因此,在BNN中的卷積計(jì)算時(shí)采用上述公式,就能完成使用1位二進(jìn)制位計(jì)算代替通常的32位計(jì)算,極大的減小了傳輸?shù)臄?shù)據(jù)量與計(jì)算量。同時(shí),在BNN計(jì)算中將卷積層、Batch-Normalization(BN)層、二值化層(將浮點(diǎn)數(shù)據(jù)變?yōu)?與-1的層)整合,通過層與層之間的整合,層之間額外的數(shù)據(jù)傳輸以及計(jì)算量得到大幅度降低,從而節(jié)省時(shí)間。同時(shí),針對(duì)移動(dòng)GPU的體系結(jié)構(gòu),PhoneBit框架采用了向量化訪存與計(jì)算、合并內(nèi)存訪問、隱藏訪存延遲、合理安排計(jì)算量負(fù)載、避免邏輯分支的判斷等計(jì)算優(yōu)化方法。相比于矢量方式1次指令只能讀取1個(gè)數(shù)據(jù),向量化方式讀寫使得計(jì)算時(shí)GPU可以只使用1次指令即可讀取若干個(gè)數(shù)據(jù)如4個(gè)、8個(gè)甚至16個(gè),達(dá)到高效利用內(nèi)存帶寬的效果;合并內(nèi)存訪問則是將GPU中同一批計(jì)算單元安排處理內(nèi)存上連續(xù)的數(shù)據(jù),這樣訪存時(shí)不需要間隔訪問,達(dá)到最大的讀寫率;隱藏訪存延遲則通過安排GPU中一批計(jì)算單元計(jì)算時(shí),另一批待計(jì)算的單元同時(shí)讀取數(shù)據(jù),避免相互等待;合理安排計(jì)算量負(fù)載則是根據(jù)計(jì)算規(guī)模的不同,調(diào)整GPU同一批計(jì)算單元進(jìn)行計(jì)算的數(shù)據(jù)量,使之不會(huì)因?yàn)橛?jì)算數(shù)據(jù)量過少而造成浪費(fèi),也不會(huì)因?yàn)閿?shù)據(jù)量過多造成擁塞。避免邏輯分支則是盡可能讓GPU中同一批計(jì)算單元執(zhí)行相同的條件分支代碼,節(jié)省執(zhí)行時(shí)間。通過以上優(yōu)化方法,PhoneBit框架速度比較如下:
于高通驍龍820平臺(tái)運(yùn)行YOLOv2 Tiny網(wǎng)絡(luò)與現(xiàn)有主流浮點(diǎn)DNN框架對(duì)比
在高通驍龍820平臺(tái),運(yùn)行YOLOv2 Tiny網(wǎng)絡(luò),相比CNNdroid(一個(gè)基于Android RenderScript的浮點(diǎn)神經(jīng)網(wǎng)絡(luò)前向傳播框架),PhoneBit框架實(shí)現(xiàn)了1218-2378倍的速度提升,2.54-4.05倍更低的功率以及89-5263倍更高的能效比。相比TensorFlow Lite(谷歌針對(duì)移動(dòng)設(shè)備提出的輕量級(jí)神經(jīng)網(wǎng)絡(luò)前向傳播框架,支持浮點(diǎn)與8bit量化模式),PhoneBit框架實(shí)現(xiàn)了10-15.6倍的速度提升,2-2.77倍更低的功率以及23.9-44倍更高的能效比。
于高通驍龍820平臺(tái)運(yùn)行Bi-Real Net 18網(wǎng)絡(luò)與現(xiàn)有基于ARM的BNN框架對(duì)比
在高通驍龍820平臺(tái),運(yùn)行Bi-Real Net 18網(wǎng)絡(luò),相比daBNN(一個(gè)最新的基于ARM高度優(yōu)化的二值神經(jīng)網(wǎng)絡(luò)框架),PhoneBit框架實(shí)現(xiàn)了2.6倍的速度提升,2.62倍更低的功率以及6.8倍更高的能效比。
PhoneBit框架使用Bi-Real Net 18網(wǎng)絡(luò)對(duì)物品進(jìn)行分類
目前,PhoneBit框架項(xiàng)目仍在不斷快速迭代進(jìn)化,框架整體性能亦在不斷提升中,希望能夠以此項(xiàng)目為相關(guān)領(lǐng)域的科研工作者、開發(fā)者們提供一個(gè)穩(wěn)定易用、高效便捷的輕量化神經(jīng)網(wǎng)絡(luò)加速引擎。同時(shí),也期望能有更多志同道合的朋友加入項(xiàng)目組,共同開發(fā)、優(yōu)化本項(xiàng)目,為PhoneBit框架的發(fā)展出一份力。
上一篇:Linux、RISC-V等基金會(huì)負(fù)責(zé)人參訪鵬城實(shí)驗(yàn)室
下一篇:推動(dòng)量子計(jì)算與AI融合,飛槳成為中國首個(gè)支持量子機(jī)器學(xué)習(xí)的深度學(xué)習(xí)平臺(tái)