沒有領域和算法限制,聯邦學習是打破數據孤島的利器
陳天健認為,聯邦學習是最有可能解決孤島問題的技術。為什么他會這樣說?
陳天健表示,和很多其他技術一樣,聯邦學習是先有英文名字:Federated Learning。在對這個技術不斷深入研究的過程中,微眾銀行的 AI 團隊發覺需要一個比較傳神的中文名字方便對中文科研與技術社區的推廣。微眾銀行首席人工智能官(CAIO),同時還是中國人工智能學會副理事長、AAAI/ACM/IEEE Fellow、IJCAI 理事長的楊強最先提議使用“聯邦學習”這個名字,以體現促進多方合作的同時保持獨立,“君子和而不同”的含義。
陳天健認為,聯邦學習中的“聯邦”更多的是強調一種開放、平等、包容的 AI 合作生態,和歷史上出現的聯邦制國家的概念還是有明顯區別的。
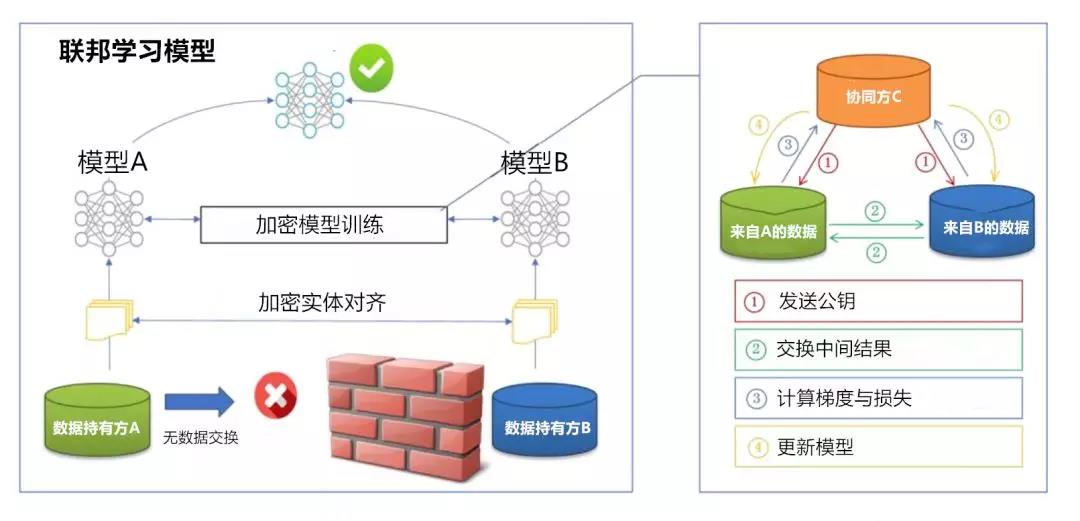
(聯邦學習系統架構)
享隱私數據的情況下,進行協同的訓練?
從 2017 年開始,大量的聯邦學習技術成果被報導出來。陳天健認為,以谷歌研究院團隊為代表的技術流派比較看重移動設備上的隱私保護問題,嘗試建立數百萬 Android 設備之間的聯邦模型,以避免用戶隱私數據上傳到數據中心后的隱私權、遺忘權實踐問題。而以微眾銀行 AI 團隊為代表的技術流派,比較看重跨機構跨組織大數據合作場景,尤其是銀行金融場景的數據安全和隱私保護問題,并且嘗試將聯邦學習框架通用化,并引入遷移學習技術進一步提高數據利用率和模型效果。
微眾銀行開源工業級聯邦學習框架
在開源上,微眾銀行走在了前面。在 GitHub 上,微眾銀行 AI 團隊已經開源了工業級的聯邦學習技術框架 Federated AI Technology Enabler(簡稱 FATE)。FATE 項目不僅提供了一系列開箱即用的聯邦學習算法、比如 LR、GBDT、CNN 等等,更重要的是給開發者提供了實現聯邦學習算法和系統的范本,大部分傳統算法都可以經過
一定改造適配到聯邦學習框架中來。
之所以叫做“工業級”的聯邦學習技術框架,主要原因是 FATE 解決了三個工業應用常見的問題
- 計算架構可并行:FATE 提供內建的并行計算機制支持大規模建模應用,百萬樣本也不是問題;
- 信息交互可審計:FATE 框架所有跨域數據交流都被獨立定義和管控起來,方便信息安全審計;
- 接口清晰可擴展:FATE 各層 IO 和計算接口均被很好抽象,方便進行各種計算機制 / 數據庫的對接。
哪個技術處理隱私問題最直接有效?
陳天健告訴 AI 前線,TensorFlow Privacy 是一個實驗性項目,主要是利用差分隱私技術對模型進行轉換,防止模型樣本數據通過無數次推理被反向解算。而 HE-Transformer 在設計上更多是讓模型可以計算同態加密過的用戶數據以完成推理過程,避免在推理過程中使用用戶原始數據。這些技術的源頭非常早了,早期的加密機器學習都是這個路數。但對建模階段的數據保護,僅僅用同態加密或者差分隱私很難完成,上述兩個框架都沒有解決方案。真正要完整解決建模 + 預測全流程全生命周期的數據安全與隱私保護問題,需要深度結合機器學習和 MPC 兩個技術領域,這就是聯邦學習的天下了。
相對 TensorFlow Privacy 來說,TensorFlow Federated 項目方便了開發者開發橫向聯邦學習應用,“我覺得應該更多關注 TensorFlow Federated。”在數據隱私保護這一問題上,陳天健給出了他的看法。
微眾銀行在信貸風控、客戶權益定價和監管科技領域同時在推動一系列聯邦學習的應用落地,比如小微企業信貸風控上,模型的性能每提高模型 1% 都很困難,微眾銀行使用銀行數據和發票數據進行聯邦學習建模后,效果比單獨使用銀行數據提高了 12%;再如,銀行如果想為客戶解決差異化權益定價、由于數據傾斜的問題,通常只能覆蓋 8%~12% 的客戶,而微眾銀行使用銀行數據和互聯網數據進行聯合建模之后,覆蓋率提升到 92%,大幅提升了銷售轉化水平。
另外,在監管科技領域,微眾銀行在央行的支持下正在協同各家銀行建立聯邦反洗錢模型,落實國家加強金融監管的相關政策,解決該領域樣本少,數據質量低問題。
陳天健表示,因為聯邦學習既是一個技術也是一個合作接口標準,業界通過 IEEE 標準的形式將對接標準固定下來,可以保證各方的聯邦學習系統能夠沒有障礙地溝通合作,而不會因為各方實現的微小技術差異而導致社區碎片化。
陳天健表示,聯邦學習是一種面向安全合規的大數據合作的機器學習技術,應用前景十分廣泛,并沒有特別的領域或者具體的算法限制,微眾銀行甚至已經在機器視覺、裝備故障檢測等應用中和領域合作伙伴開展技術合作,推動聯邦學習社區進一步發展。
隨著 5G IoT 技術的進一步發展,設備間傳輸帶寬的大幅改善以及邊緣計算性能的增強,聯邦學習也將用于 5G IoT 網絡基礎之上的 AI 能力提升和生態構建。
我們可以從中看出,聯邦學習的未來可期,我們也期待聯邦學習在未來能有更多的應用盡快落地,解決數據隱私這一越來越嚴重且全世界人類最關注的問題之一。
來源:AI前線
采訪嘉賓:陳天健
整理&編輯:Debra
上一篇:全國高校人工智能學院論壇:產教融合,人工智能人才培養該如何推進?
下一篇:PNAS評論:深度學習未達預期,圖網絡有望引領下一次AI革命