pRPC 零拷貝高性能網(wǎng)絡通信協(xié)議
pRPC 零拷貝高性能網(wǎng)絡通信協(xié)議 貢獻者: 第四范式 許可證:Apache License 2.0
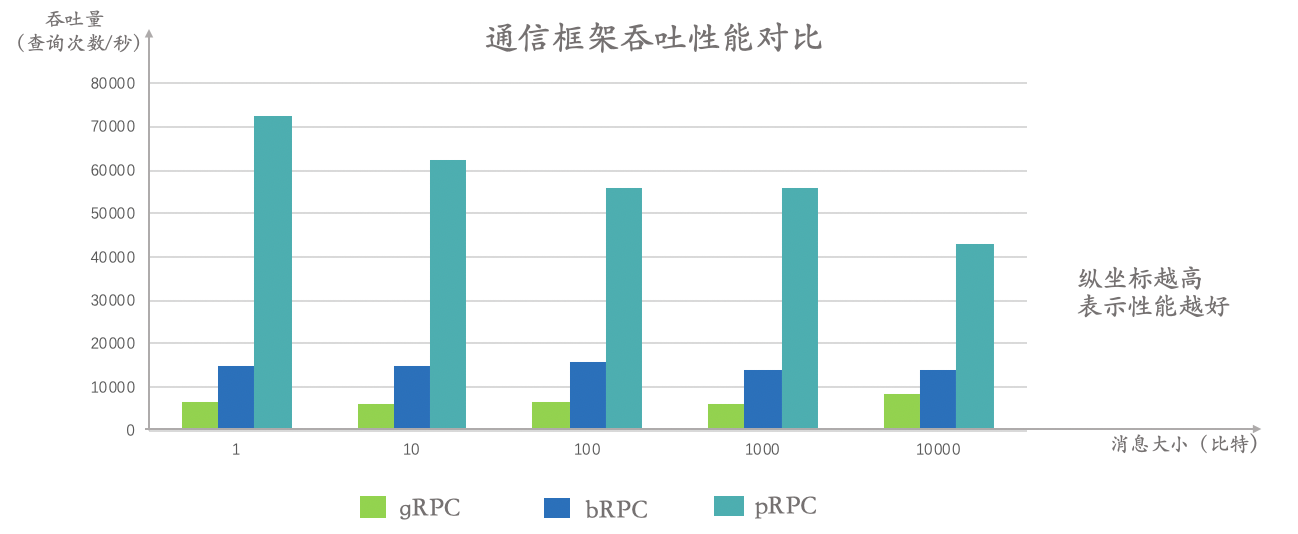
pRPC 面向AI模型訓練中大規(guī)模的數(shù)據(jù)和參數(shù)移動負載特性進行優(yōu)化,相比百度bRPC、Google gRPC等通用網(wǎng)絡通信框架,實現(xiàn)高達10倍的網(wǎng)絡通信性能提升。
pRPC是一個面向機器學習工作負載的高性能網(wǎng)絡通信框架,通過內(nèi)存零拷貝設計實現(xiàn)更快的網(wǎng)絡通信、以及更高的數(shù)據(jù)移動吞吐,針對機器學習工作負載中梯度計算、參數(shù)同步等環(huán)節(jié)的突發(fā)流量,在保障線程安全的情況下,提供消息級負載均衡,支持結(jié)合100G+RDMA遠程直接內(nèi)存訪問技術(shù),實現(xiàn)序列化與反序列化中的高效處理,突破TCP的性能瓶頸,最大化分布式計算性能,解決機器學習分布式訓練中的網(wǎng)絡瓶頸。
不同類型的AI算法在訓練過程中面臨不同的網(wǎng)絡性能瓶頸,消息吞吐量制約處理大規(guī)模離散特征的算法(如LR等)的訓練性能,網(wǎng)絡延遲制約處理稠密特征的算法(如深度學習算法或者樹模型等)。
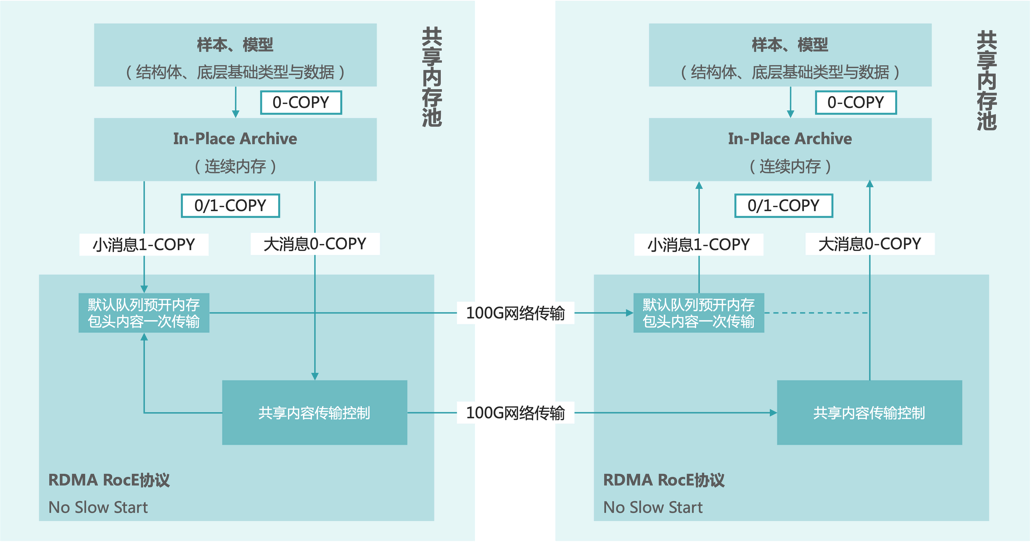
無鎖排隊與批量消息處理的線程安全技術(shù),減少線程跳轉(zhuǎn)與緩存同步
支持RDMA,繞過TCP,解決slow start的問題;RDMA實現(xiàn)網(wǎng)卡對內(nèi)存的訪問,直接發(fā)揮硬件的最大價值
應用層內(nèi)存共享技術(shù),減少數(shù)據(jù)在內(nèi)存、網(wǎng)卡間、客戶端與服務端間的冗余拷貝
pRPC架構(gòu)
pRPC 面向AI模型訓練中大規(guī)模的數(shù)據(jù)和參數(shù)移動負載特性進行優(yōu)化,相比百度bRPC、Google gRPC等通用網(wǎng)絡通信框架,實現(xiàn)高達10倍的網(wǎng)絡通信性能提升。