當(dāng)前位置:首頁 > 資訊 > 社區(qū)動態(tài) >
近年來,隨著預(yù)訓(xùn)練語言模型技術(shù)引發(fā)人工智能領(lǐng)域性能革命,大規(guī)模預(yù)訓(xùn)練模型技術(shù)的成熟標(biāo)志著“大模型時代”的到來。然而在大模型的具體應(yīng)用與落地中,卻存在著“訓(xùn)練難、微調(diào)難、應(yīng)用難”三大挑戰(zhàn)。
為此,清華大學(xué)自然語言處理實驗室和智源研究院語言大模型加速技術(shù)創(chuàng)新中心共同支持發(fā)起了OpenBMB(Open Lab for Big Model Base)開源社區(qū),旨在打造大規(guī)模預(yù)訓(xùn)練語言模型庫與相關(guān)工具,加速百億級以上大模型的訓(xùn)練、微調(diào)與推理,降低大模型使用門檻,實現(xiàn)大模型的標(biāo)準(zhǔn)化、普及化和實用化。
為了讓大模型飛入千家萬戶,OpenBMB開源社區(qū)、鵬城實驗室,以及OpenI啟智社區(qū)已攜手進(jìn)行國內(nèi)獨家開源合作,將共同推動大模型在人工智能開源領(lǐng)域的發(fā)展與普及。目前,OpenBMB社區(qū)已正式入駐并將其部分模型套件開源部署至OpenI啟智社區(qū),計劃通過OpenI啟智社區(qū)進(jìn)行代碼和數(shù)據(jù)集的開放管理,匯聚更多開源開發(fā)者的力量,以及基于鵬城云腦科學(xué)裝置提供的算力資源,進(jìn)一步推進(jìn)OpenBMB系列大模型套件的開發(fā)與訓(xùn)練。
歡迎大家訪問OpenBMB開源社區(qū)主頁鏈接,參與代碼貢獻(xiàn)與支持社區(qū)建設(shè)。
https://git.www.cnjfsc.com/OpenBMB
近年來人工智能和深度學(xué)習(xí)技術(shù)飛速發(fā)展,極大改變了我們的日常工作與生活。伴隨人類社會信息化產(chǎn)生海量數(shù)據(jù),人工智能技術(shù)能夠有效學(xué)習(xí)數(shù)據(jù)的分布與特征,對數(shù)據(jù)進(jìn)行深入分析并完成復(fù)雜智能任務(wù),產(chǎn)生巨大的經(jīng)濟(jì)與社會價值,人類社會步入了“大數(shù)據(jù)時代”。
當(dāng)前人工智能算法的典型流程為:準(zhǔn)備數(shù)據(jù)、訓(xùn)練模型和部署模型。其挑戰(zhàn)在于,針對給定任務(wù)人工標(biāo)注訓(xùn)練數(shù)據(jù)注費時費力,數(shù)據(jù)規(guī)模往往有限,需要承擔(dān)算法性能不達(dá)標(biāo)、模型泛化能力差等諸多風(fēng)險,導(dǎo)致人工智能面臨研發(fā)周期長、風(fēng)險大、投入成本高的困局,阻礙了人工智能算法的落地與推廣。
2018年預(yù)訓(xùn)練語言模型技術(shù)橫空出世,形成了“預(yù)訓(xùn)練-微調(diào)”的新研發(fā)范式,極大地改變了上述困局。在這個新范式下,我們可以非常容易地搜集大規(guī)模無標(biāo)注語料,采用自監(jiān)督學(xué)習(xí)技術(shù)預(yù)訓(xùn)練語言模型;然后可以利用特定下游任務(wù)對應(yīng)的訓(xùn)練數(shù)據(jù),進(jìn)一步微調(diào)更新模型參數(shù),讓該模型掌握完成下游任務(wù)的能力。大量研究結(jié)果證明,預(yù)訓(xùn)練語言模型能夠在自然語言處理等領(lǐng)域的廣大下游任務(wù)上取得巨大的性能提升,并快速成長為人工智能生態(tài)中的基礎(chǔ)設(shè)施。
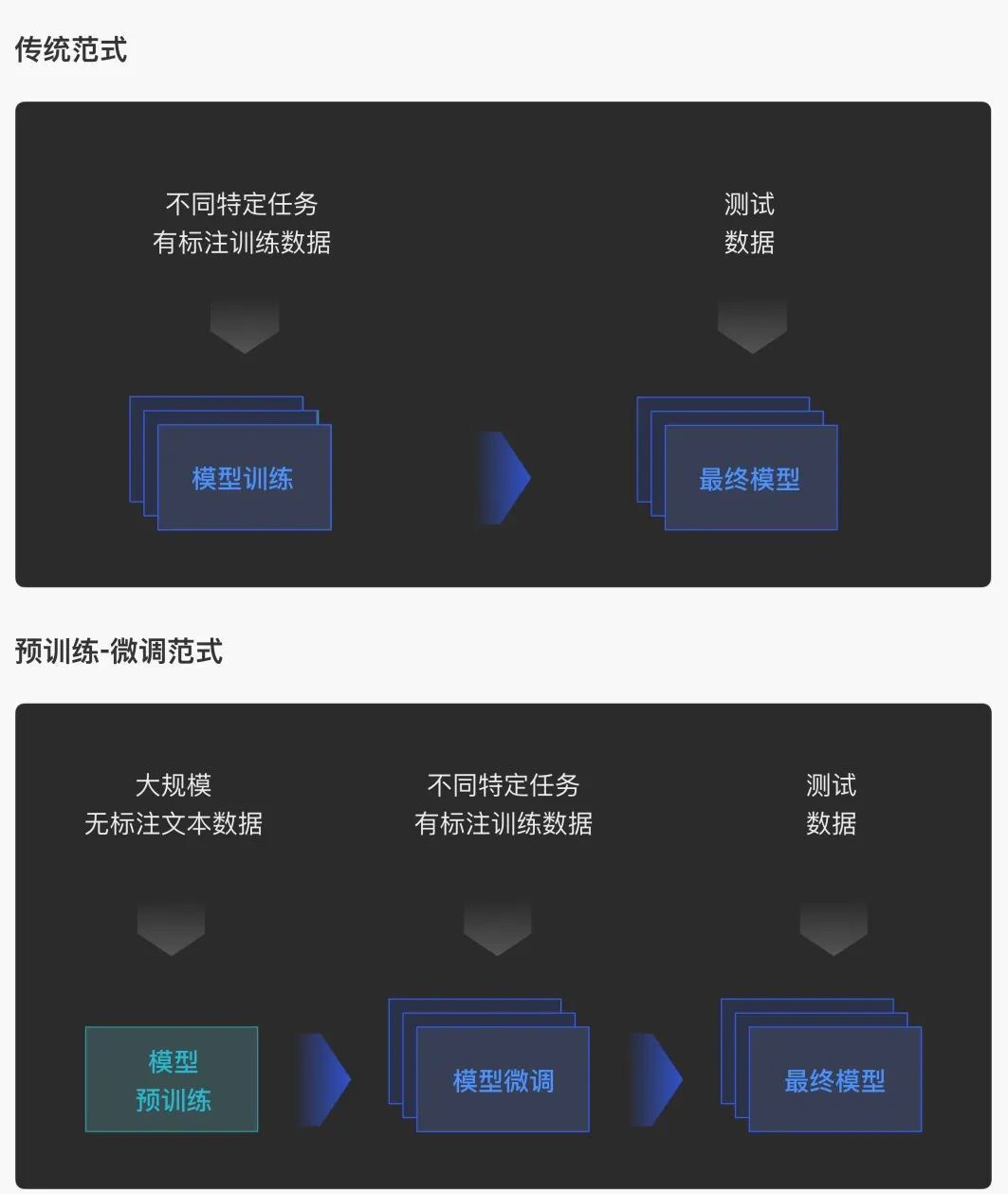
預(yù)訓(xùn)練 - 微調(diào)范式對比傳統(tǒng)范式
通過充分利用互聯(lián)網(wǎng)上近乎無窮的海量數(shù)據(jù),預(yù)訓(xùn)練模型正在引發(fā)一場人工智能的性能革命。研究表明,更大的參數(shù)規(guī)模為模型性能帶來質(zhì)的飛躍。對十億、百億乃至千億級超大模型的探索成為業(yè)界的熱門話題,引發(fā)國內(nèi)外著名互聯(lián)網(wǎng)企業(yè)和研究機構(gòu)的激烈競爭,將模型規(guī)模和性能不斷推向新的高度。除Google、OpenAI等國外知名機構(gòu)外,近年來國內(nèi)相關(guān)研究機構(gòu)與公司也異軍突起,形成了大模型的研究與應(yīng)用熱潮。圍繞大模型展開的"軍備競賽"日益白熱化,成為對海量數(shù)據(jù)、并行計算、模型學(xué)習(xí)和任務(wù)適配能力的全方位考驗,人工智能進(jìn)入“大模型時代”。
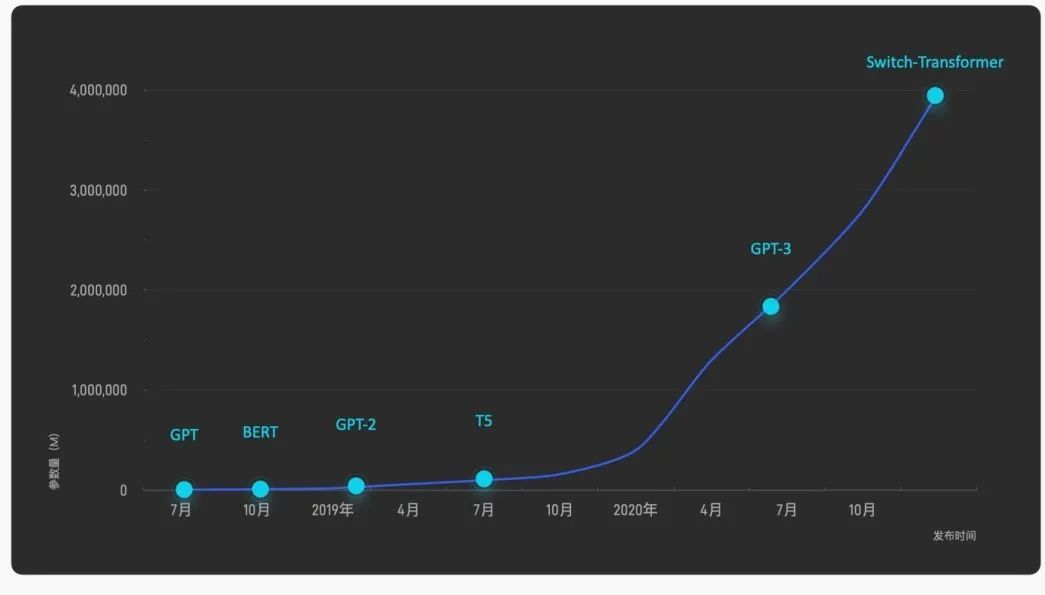
國內(nèi)外知名機構(gòu)在大模型訓(xùn)練中持續(xù)投入
然而在“大模型時代”,因為大模型巨大的參數(shù)量和算力需求,在大范圍內(nèi)應(yīng)用大模型仍然存在著較大的挑戰(zhàn)。如何讓更多開發(fā)者方便享用大模型,如何讓更多企業(yè)廣泛應(yīng)用大模型,讓大模型不再“大”不可及,是實現(xiàn)大模型可持續(xù)發(fā)展的關(guān)鍵。與普通規(guī)模的深度學(xué)習(xí)模型相比,大模型訓(xùn)練與應(yīng)用需要重點突破三大挑戰(zhàn):
? 訓(xùn)練難:訓(xùn)練數(shù)據(jù)量大,算力成本高。
? 微調(diào)難:微調(diào)參數(shù)量大,微調(diào)時間長。
? 應(yīng)用難:推理速度慢,響應(yīng)時間長,難以滿足線上業(yè)務(wù)需求。
為了讓大模型技術(shù)更好地普及應(yīng)用,針對這些挑戰(zhàn),清華大學(xué)自然語言處理實驗室和智源研究院語言大模型加速技術(shù)創(chuàng)新中心成立了OpenBMB開源社區(qū)。
謀定而動,OpenBMB將從數(shù)據(jù)、工具、模型、協(xié)議四個層面構(gòu)建應(yīng)用便捷、能力全面、使用規(guī)范的大規(guī)模預(yù)訓(xùn)練模型庫。
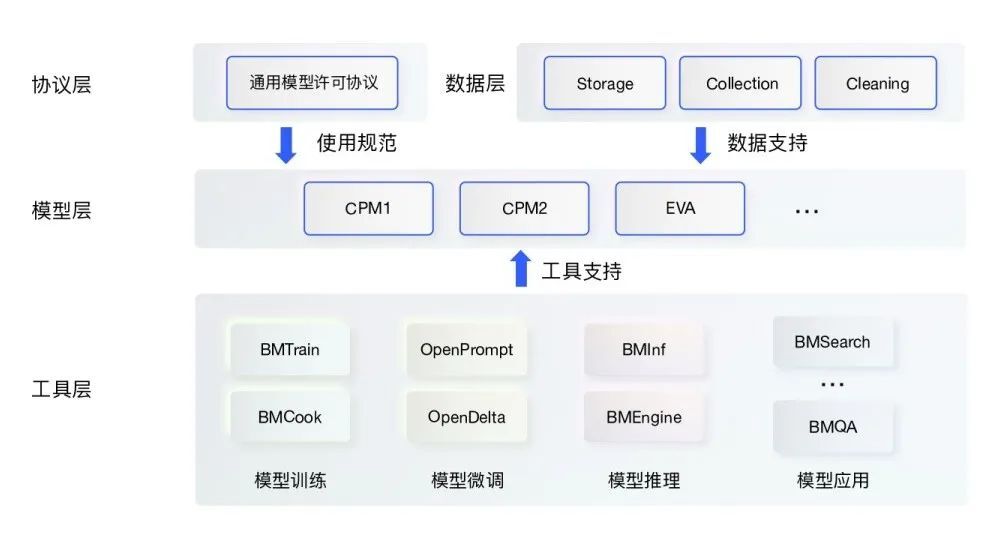
OpenBMB 能力體系
OpenBMB能力體系具體包括:
? 數(shù)據(jù)層:構(gòu)建大規(guī)模數(shù)據(jù)自動收集、自動清洗、高效存儲模塊與相關(guān)工具,為大模型訓(xùn)練提供數(shù)據(jù)支持。
? 工具層:聚焦模型訓(xùn)練、模型微調(diào)、模型推理、模型應(yīng)用四個大模型主要場景,推出配套開源工具包,提升各環(huán)節(jié)效率,降低計算和人力成本。
? 模型層:構(gòu)建OpenBMB工具支持的開源大模型庫,包括BERT、GPT、T5等通用大模型和CPM、EVA、GLM等悟道開源大模型,并不斷完善添加新模型,形成覆蓋全面的模型能力。
? 協(xié)議層:發(fā)布通用模型許可協(xié)議,規(guī)范與保護(hù)大模型發(fā)布使用過程中發(fā)布者與使用者權(quán)利與義務(wù),目前協(xié)議初稿已經(jīng)開源(https://www.openbmb.org/license)。
大模型相關(guān)工具在OpenBMB能力體系中發(fā)揮著核心作用。OpenBMB將努力建設(shè)大模型開源社區(qū),團(tuán)結(jié)廣大開發(fā)者不斷完善大模型從訓(xùn)練、微調(diào)、推理到應(yīng)用的全流程配套工具。基于發(fā)起人團(tuán)隊前期工作,OpenBMB設(shè)計了大模型全流程研發(fā)框架,并初步開發(fā)了相關(guān)工具,這些工具各司其職、相互協(xié)作,共同實現(xiàn)大模型從訓(xùn)練、微調(diào)到推理的全流程高效計算。
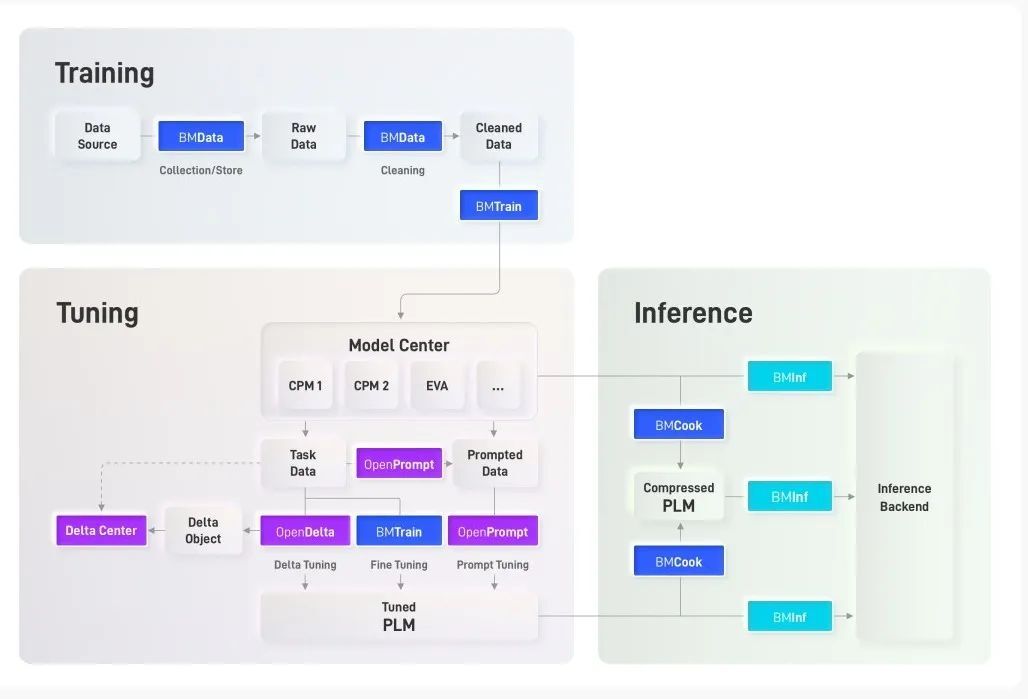
OpenBMB 工具架構(gòu)圖
模型訓(xùn)練套件
BMTrain:大模型訓(xùn)練“發(fā)動機”。BMTrain進(jìn)行高效的大模型預(yù)訓(xùn)練與微調(diào)。與DeepSpeed等框架相比,BMTrain訓(xùn)練模型成本可節(jié)省90%。
開源地址如下:
https://git.www.cnjfsc.com/OpenBMB/BMTrain
BMCook:大模型“瘦身”工具庫。BMCook進(jìn)行大模型高效壓縮,提高運行效率。通過量化、剪枝、蒸餾、專家化等算法組合,可保持原模型90%+效果,模型推理加速10倍。
開源地址如下:
https://git.www.cnjfsc.com/OpenBMB/BMCook
BMData:大模型“原料”收集器。BMData進(jìn)行高質(zhì)量數(shù)據(jù)清洗、處理與存儲,為大模型訓(xùn)練提供全面、綜合的數(shù)據(jù)支持。
模型微調(diào)套件
OpenPrompt:大模型提示學(xué)習(xí)利器。OpenPrompt提供統(tǒng)一接口的提示學(xué)習(xí)模板語言,2021年發(fā)布以來在國外某開源社區(qū)獲得1.3k星標(biāo),每周訪問量10k+。
OpenDelta:“小”參數(shù)撬動“大”模型。OpenDelta進(jìn)行參數(shù)高效的大模型微調(diào),僅更新極少參數(shù)(小于5%)即可達(dá)到全參數(shù)微調(diào)的效果。
Delta Center:“人人為我,我為人人” - Delta Object分享中心。Delta Center提供Delta Object的上傳、分享、檢索、下載功能,鼓勵社區(qū)開發(fā)者共享大模型能力。
模型推理套件
BMInf:千元級顯卡玩轉(zhuǎn)大模型推理。BMInf實現(xiàn)大模型低成本高效推理計算,使用單塊千元級顯卡(GTX 1060)即可進(jìn)行百億參數(shù)大模型推理。2021年發(fā)布以來在國外某開源社區(qū)獲得200+星標(biāo)。
開源地址如下:
https://git.www.cnjfsc.com/OpenBMB/BMInf
近期,OpenBMB開源社區(qū)已將部分完成開發(fā)的推理套件BMInf、訓(xùn)練套件BMCook和BMTrain上傳與開源至OpenI啟智社區(qū),而后續(xù)也會將全部工具開源上來。未來,OpenBMB將依托自有開源社區(qū)和OpenI啟智社區(qū)開源的力量,與廣大開發(fā)者一道共同打磨和完善大模型相關(guān)工具,助力大模型應(yīng)用與落地。期待廣大開發(fā)者關(guān)注和貢獻(xiàn)OpenBMB!
OpenBMB開源社區(qū)由清華大學(xué)自然語言處理實驗室和智源研究院語言大模型加速技術(shù)創(chuàng)新中心共同支持發(fā)起。
發(fā)起團(tuán)隊擁有深厚的自然語言處理和預(yù)訓(xùn)練模型研究基礎(chǔ),曾最早提出知識指導(dǎo)的預(yù)訓(xùn)練模型ERNIE并發(fā)表在自然語言處理頂級國際會議ACL 2019上,累計被引超過600次,被學(xué)術(shù)界公認(rèn)為融合知識的預(yù)訓(xùn)練語言模型的代表方法,被美國國家醫(yī)學(xué)院院士團(tuán)隊用于研制醫(yī)學(xué)診斷領(lǐng)域的自動問答系統(tǒng);團(tuán)隊依托智源研究院研發(fā)的“悟道·文源”中文大規(guī)模預(yù)訓(xùn)練語言模型CPM-1、CPM-2,參數(shù)量最高達(dá)到1980億,在眾多下游任務(wù)中取得優(yōu)異性能;團(tuán)隊近年來圍繞模型預(yù)訓(xùn)練、提示學(xué)習(xí)、模型壓縮技術(shù)等方面在頂級國際會議上發(fā)表了數(shù)十篇高水平論文,2022年面向生物醫(yī)學(xué)的預(yù)訓(xùn)練模型KV-PLM發(fā)表在著名綜合類期刊Nature Communications上,并入選該刊亮點推薦文章,相關(guān)論文列表詳見文末。
團(tuán)隊還有豐富的自然語言處理技術(shù)的開源經(jīng)驗,發(fā)布了OpenKE、OpenNRE、OpenNE等一系列有世界影響力的工具包,在GitHub上累計獲得超過5.8萬星標(biāo),位列全球機構(gòu)第148位,曾獲教育部自然科學(xué)一等獎、中國中文信息學(xué)會錢偉長中文信息處理科學(xué)技術(shù)獎一等獎等成果獎勵。
發(fā)起團(tuán)隊面向OpenBMB開源社區(qū)研制發(fā)布的BMInf、OpenPrompt、OpenDelta等工具包已陸續(xù)發(fā)表在自然語言處理頂級國際會議ACL 2022上。
OpenBMB主要發(fā)起人介紹
孫茂松
清華大學(xué)計算機系教授,智源研究院自然語言處理方向首席科學(xué)家,清華大學(xué)人工智能研究院常務(wù)副院長,清華大學(xué)計算機學(xué)位評定分委員會主席,歐洲科學(xué)院外籍院士。主要研究方向為自然語言處理、人工智能、社會人文計算和計算教育學(xué)。在人工智能領(lǐng)域的著名國際期刊和會議發(fā)表相關(guān)論文400余篇,Google Scholar統(tǒng)計引用超過2萬次。曾獲全國優(yōu)秀科技工作者、教育部自然科學(xué)一等獎、中國中文信息學(xué)會錢偉長中文信息處理科學(xué)技術(shù)獎一等獎,享受國務(wù)院政府特殊津貼。
劉知遠(yuǎn)
清華大學(xué)計算機系副教授,智源青年科學(xué)家。主要研究方向為自然語言處理、知識圖譜和社會計算。在人工智能領(lǐng)域著名國際期刊和會議發(fā)表相關(guān)論文200余篇,Google Scholar統(tǒng)計引用超過2萬次。曾獲教育部自然科學(xué)一等獎(第2完成人)、中國中文信息學(xué)會錢偉長中文信息處理科學(xué)技術(shù)獎一等獎(第2完成人)、中國中文信息學(xué)會漢王青年創(chuàng)新獎,入選國家青年人才計劃、2020年Elsevier中國高被引學(xué)者、《麻省理工科技評論》中國區(qū)35歲以下科技創(chuàng)新35人榜單、中國科協(xié)青年人才托舉工程。
韓旭
清華大學(xué)計算機系博士生,研究方向為自然語言處理、預(yù)訓(xùn)練語言模型和知識計算,在人工智能領(lǐng)域著名國際期刊和會議ACL、EMNLP上發(fā)表多篇論文,悟道·文源中文預(yù)訓(xùn)練模型團(tuán)隊骨干成員,CPM-1、CPM-2、ERNIE的主要作者之一。曾獲2011年全國青少年信息學(xué)競賽金牌(全國40人)、國家獎學(xué)金、清華大學(xué)“蔣南翔”獎學(xué)金、清華大學(xué)“鐘士模”獎學(xué)金、微軟學(xué)者獎學(xué)金(亞洲12人)、清華大學(xué)優(yōu)良畢業(yè)生等榮譽。
曾國洋
清華大學(xué)計算機系畢業(yè)生,智源研究院語言大模型加速技術(shù)創(chuàng)新中心副主任。擁有豐富人工智能項目開發(fā)與管理經(jīng)驗,悟道·文源中文預(yù)訓(xùn)練模型團(tuán)隊骨干成員,BMTrain、BMInf的主要作者之一。曾獲2015年全國青少年信息學(xué)競賽金牌(全國50人)、亞太地區(qū)信息學(xué)競賽金牌、清華大學(xué)挑戰(zhàn)杯一等獎、首都大學(xué)生挑戰(zhàn)杯一等獎。
丁寧
清華大學(xué)計算機系博士生,研究方向為機器學(xué)習(xí)、預(yù)訓(xùn)練語言模型和知識計算,在人工智能領(lǐng)域著名國際期刊和會議ICLR、ACL、EMNLP上發(fā)表多篇論文,悟道·文源中文預(yù)訓(xùn)練模型團(tuán)隊骨干成員,OpenPrompt、OpenDelta的主要作者之一。曾獲國家獎學(xué)金、清華大學(xué)“清峰”獎學(xué)金、百度獎學(xué)金(全國10人)等榮譽。
張正彥
清華大學(xué)計算機系博士生,研究方向為自然語言處理和預(yù)訓(xùn)練語言模型,在人工智能領(lǐng)域著名國際期刊和會議ACL、EMNLP、TKDE上發(fā)表多篇論文,悟道·文源中文預(yù)訓(xùn)練模型團(tuán)隊骨干成員,CPM-1、CPM-2、ERNIE的主要作者之一。曾獲國家獎學(xué)金、清華大學(xué)優(yōu)良畢業(yè)生、清華大學(xué)優(yōu)秀本科畢業(yè)論文等榮譽。
結(jié)語
OpenI啟智社區(qū)是以鵬城云腦科學(xué)裝置及軟件開發(fā)群智范式為基礎(chǔ),由新一代人工智能產(chǎn)業(yè)技術(shù)創(chuàng)新戰(zhàn)略聯(lián)盟(AITISA)組織產(chǎn)學(xué)研用協(xié)作共建共享的開源平臺與社區(qū)。
無論你正在從事大模型研究,研發(fā)大模型應(yīng)用,還是對大模型技術(shù)充滿興趣,歡迎來OpenI啟智社區(qū)使用OpenBMB開源工具和模型庫。OpenBMB開源社區(qū)推崇簡捷,追求極致,相信數(shù)據(jù)與模型的力量。歡迎志同道合的你加入,共同為大模型應(yīng)用落地添磚加瓦,早日讓大模型飛入千家萬戶。
OpenBMB相關(guān)鏈接
? 開源主頁:
https://git.www.cnjfsc.com/OpenBMB
? 官方網(wǎng)站:
https://www.openbmb.org
? 交流QQ群:
735930538
? 微博:
http://weibo.cn/OpenBMB
? 郵箱:
openbmb@gmail.com
? 知乎:
https://www.zhihu.com/people/OpenBMB
? Twitter:
https://twitter.com/OpenBMB
附錄 團(tuán)隊論文發(fā)布列表
1. Zhengyan Zhang, Xu Han, Zhiyuan Liu et al. ERNIE: Enhanced Language Representation with Informative Entities. ACL 2019.
2. Xiaozhi Wang, Tianyu Gao, Zhaocheng Zhu et al. KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation. TACL 2021.
3. Yujia Qin, Yankai Lin, Ryuichi Takanobu et al. ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive Learning. ACL-IJCNLP 2021.
4. Xu Han, Zhengyan Zhang, Ning Ding et al. Pre-Trained Models: Past, Present and Future. AI Open 2021.
5. Zhengyan Zhang, Xu Han, Hao Zhou et al. CPM: A Large-scale Generative Chinese Pre-trained Language Model. AI Open 2021.
6. Zheni Zeng, Yuan Yao, Zhiyuan Liu, Maosong Sun. A Deep-learning System Bridging Molecule Structure and Biomedical Text with Comprehension Comparable to Human Professionals. Nature Communications 2022.
7. Ning Ding, Yujia Qin, Guang Yang et al. Delta Tuning: A Comprehensive Study of Parameter Efficient Methods for Pre-trained Language Models. Arxiv 2022.
8. Zhengyan Zhang, Yuxian Gu, Xu Han et al. CPM-2: Large-scale Cost-effective Pre-trained Language Models. AI Open 2022.
9. Ganqu Cui, Shengding Hu, Ning Ding et al. Prototypical Verbalizer for Prompt-based Few-shot Tuning. ACL 2022.
10. Shengding Hu, Ning Ding, Huadong Wang et al. Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification. ACL 2022.
11. Yujia Qin, Jiajie Zhang, Yankai Lin et al. ELLE: Efficient Lifelong Pre-training for Emerging Data. Findings of ACL 2022.
12. Yuan Yao, Bowen Dong, Ao Zhang et al. Prompt Tuning for Discriminative Pre-trained Language Models. Findings of ACL 2022.
13. Ning Ding, Shengding Hu, Weilin Zhao et al. OpenPrompt: An Open-source Framework for Prompt-learning. ACL 2022 Demo.
14. Han Xu, Guoyang Zeng, Weilin Zhao et al. BMInf: An Efficient Toolkit for Big Model Inference and Tuning. ACL 2022 Demo.