百度開源AI視頻大賽奪冠模型,手把手教你用PaddlePaddle實戰
計算機視覺頂會CVPR上,有一項名叫ActivityNet Kinetics Challenge的比賽,就是這類算法的競技場。2018年的冠軍,正來自百度視覺組。
現在,他們的奪冠模型StNet開源了。百度工程師們還寫了一篇文章,從架構到用法詳細介紹了這個模型。
百度視覺技術部聯合PaddlePaddle團隊近期開源了用于視頻分類的StNet框架。StNet框架為ActivityNet Kinetics Challenge 2018中奪冠的網絡框架。本次開源了基于ResNet50實現的StNet模型。
該模型提出“super-image”的概念,在super-image上進行2D卷積,建模視頻中局部時空相關性。另外通過temporal modeling block建模視頻的全局時空依賴,最后用一個temporal Xception block對抽取的特征序列進行長時序建模。
該框架在動作識別方面優于一些最先進的方法,可以在識別精度和模型復雜性之間取得令人滿意的平衡。
應用背景
視頻當中的動作識別任務已經獲得了許多從事計算機視覺與機器學習研究人員的重點關注。越來越多的視頻錄像設備的普及,讓更多好玩有趣的視頻豐富了人們的業余生活。但是過多的視頻已經遠遠超過人工能夠處理的范圍,因此發展針對各種應用場景的自動視頻理解算法變得尤為重要,比如:視頻推薦、人類行為分析、視頻監控等等。
深度學習在靜態圖像理解上取得了巨大成功,但是針對視頻時空建模中最有效的網絡架構是什么還尚不清楚,因此我們將新探索的用于視頻中局部和全局時空建模的時空網絡(StNet)架構與現有的CNN+RNN模型或是基于純3D卷積的方法進行比對分析,來尋求更有效的網絡架構。
現有方法分析
由于深度學習在圖片識別中的卓越表現,該技術也被應用到了解決視頻分類的場景當中。這其中就有兩個主要的研究方向,一個是應用CNN+RNN框架結構來對視頻序列建模,還有一個是單純的利用卷積網絡結構來識別視頻當中的行為。但是在動作識別準確性方面,目前的行動識別方法仍然遠遠落后于人類表現。現有方法存在如下待改進之處。
CNN+RNN模型
對于CNN+RNN的方法,CNN前饋網絡部分用來空間建模(spatial modeling),LSTM或者GRU用來時域建模(temporal modeling),由于該模型自身的循環結構,這導致了端到端的優化困難。單獨訓練的CNN和RNN部分對于聯合的時空特征表示學習(representation learning)不是最佳的。
純卷積網絡結構
2D卷積網絡結構在抽取外觀特征(appearance features)的時候,只利用了局部的空間信息而忽略了局部的時域信息;此外,對于時域動態,2D卷積網絡僅融合了幾個局部片段的分類得分并計算平均值,這種取平均的方法在捕捉時空信息方面的性能有待提高。3D卷積網絡結構可以同時在空間和時間上建模進而得到令人滿意的識別任務結果。眾所周知,淺層的神經網絡與深層神經網絡相比,淺層網絡在大數據集中,表現出較差的表示學習能力。當進行大規模數據集中的人類行為識別任務時,一方面淺層的3D卷積網絡得到的視頻特征的可辨別性相對深層網絡較弱,另一方面,深層的3D卷積網絡會導致過大的模型以及在訓練中和推理階段中過高的計算成本。
StNet模型
局部信息和全局信息對識別視頻中的行為都起著非常重要的作用。
例如,在圖1(a)中,我們可以通過局部的空間信息來識別搬磚和搬石頭,換而言之,在該圖中,局部的空間信息(local spatial information)是我們識別行為至關重要的因素。而在圖1(b)中,全局時空(global spatial-temporal)線索是用來區分”摞卡片”和”飛卡片”這兩個場景行為的關鍵證據。

圖1局部信息足以區分”搬磚”和”搬石頭”;全局時空信息可以分別”摞卡片”和”飛卡牌”
StNet可以由先進的2D卷積網絡改造可得,比如:ResNet、InceptionResnet等等。圖2展示了如何從Resnet構建StNet。
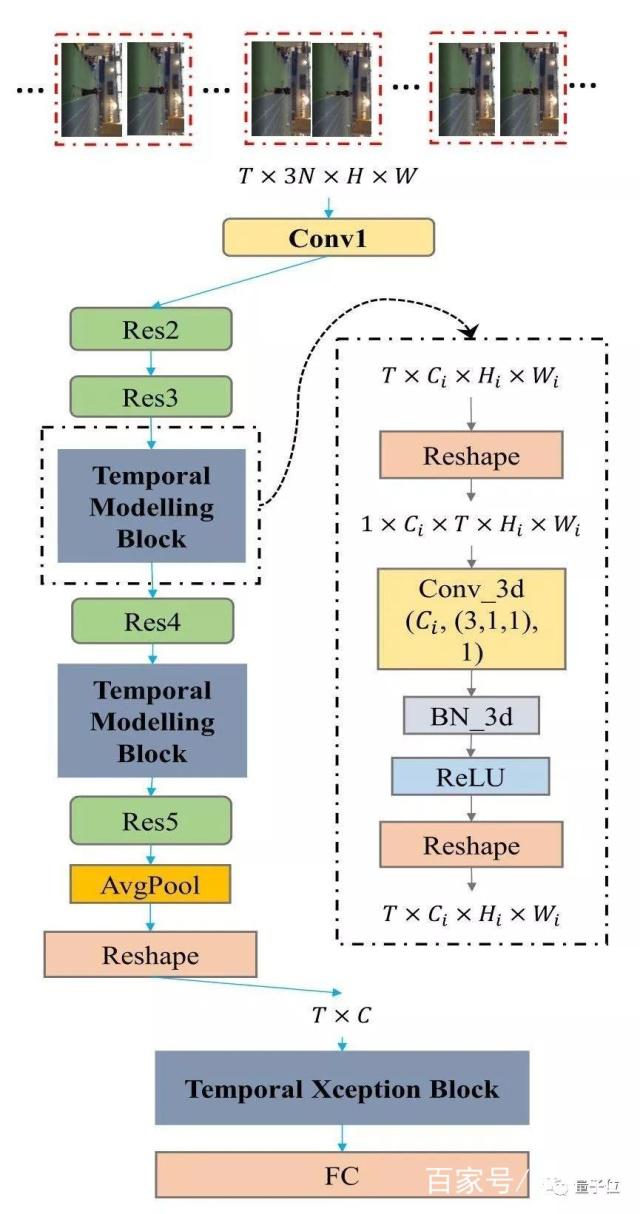
圖2:基于ResNet骨架構建的StNet。
StNet的輸入是T ×3N ×H ×W張量。通過2D卷積對局部時空模型進行模型。在Res3和Res4塊之后插入時序卷積模塊進行全局時空特征建模。最后,用時序Xception模塊進一步建模時序動態信息。3D卷積的設置是(# Output Channel, (temporal kernel size, height kernel size, width kernel size), # groups) -(Ci, (3,1,1), 1)
超圖像(Super-Image):
StNet的輸入為均勻采樣的T個局部連續N幀的視頻幀。局部的連續N幀組合成一個”超圖”,這使得”超圖”保留原始視頻各個局部的時空信息。所以網絡的輸入是一個尺寸為T*3N*H*W的張量。
時域建模塊(Temporal Modeling Block):
采用2D卷積對T個”超圖”進行局部時空關系的建模,可以避免 3D 卷積網絡參數量和計算量大的問題,進而生成T個局部時空特征圖。通過堆疊3D卷積/2D卷積模塊,對T個局部時空特征圖進行全局時空信息的建模,這對理解整個視頻起到至關重要的作用。
具體而言,我們選擇插入2個時域建模塊在Res3和Res4塊之后。時域建模塊是為了捕捉視頻序列內的長期時域動態,可以利用Conv_3d-BN3d-RELU架構實現。將3D卷積空間維度的kernel size設置成1以節省模型的參數量與計算量。
時域Xception模塊(Temporal Xception Block):
時域Xception模塊是為了在特征序列之間進行有效的時域建模,并能輕松地進行端到端優化。Xception模塊的設計主要基于時序1維卷積,采用了channel-wise和temporal-wise分離的策略進一步減少計算量與模型參數量。
時域Xception塊結構如下:
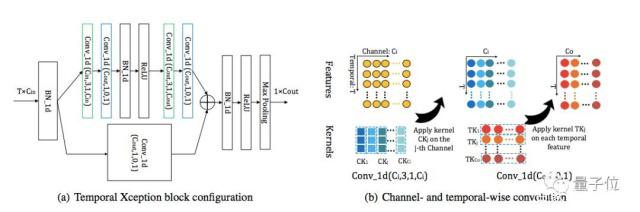
圖3:時域 Xception 塊(TXB)。
時域Xception 塊的詳細配置如(a)所示:括號中的參數表示 1D卷積的(#kernel,kernel size,padding,#groups)配置。綠色的塊表示 channel-wise 的 1D 卷積,藍色的塊表示 temporal-wise 的 1D 卷積。
(b)描繪了 channel-wise 和 temporal-wise 的 1D 卷積。TXB 的輸入是視頻的特征序列,表示為 T×C_in 張量。Channel-wise 1D 卷積的每個卷積核僅在一個通道內沿時間維度應用。Temporal-wise 的 1D 卷積核在每個時序特征中跨所有通道進行卷積
基于PaddlePaddle 實戰
環境準備:
PaddlePaddle Fluid 1.3 + cudnn5.1 。使用cudnn7.0以上版本時batchnorm計算moving mean和moving average會出現異常,此問題還在修復中。建議用戶安裝PaddlePaddle時指定cudnn版本。
數據準備:
Kinetics數據集是DeepMind公開的大規模視頻動作識別數據集,有Kinetics400與Kinetics600兩個版本。這里使用Kinetics400數據集。
ActivityNet官方提供了Kinetics的下載工具,具體參考其官方repo 即可下載Kinetics400的mp4視頻集合。
將kinetics400的訓練與驗證集合分別下載到dataset/kinetics/data_k400/train_mp4dataset/kinetics/data_k400/val_mp4。
模型訓練:
數據準備完畢后,通過以下方式啟動訓練(方法1),同時我們也提供快速啟動腳本 (方法2)
方法1
python train.py --model-name=STNET--config=./configs/stnet.txt --save-dir=checkpoints --log-interval=10 --valid-interval=1
方法2
bash scripts/train/train_stnet.sh
用戶也可下載Paddle Github上已發布模型通過—resume指定權重存放路徑進行finetune等開發。
數據預處理說明:
模型讀取Kinetics-400數據集中的mp4數據,每條數據抽取seg_num段,每段抽取seg_len幀圖像,對每幀圖像做隨機增強后,縮放至target_size。
訓練策略:
采用Momentum優化算法訓練,momentum=0.9權重衰減系數為1e-4學習率在訓練的總epoch數的1/3和2/3時分別做0.1的衰減
模型評估:
通過以下方式(方法 1)進行模型評估,同樣我們也提供了快速啟動的腳本(方法 2):
方法1
python test.py --model-name=STNET--config=configs/stnet.txt --log-interval=1 --weights=$PATH_TO_WEIGHTS
方法2
bash scripts/test/test__stnet.sh
使用scripts/test/test_stnet.sh進行評估時,需要修改腳本中的—weights參數指定需要評估的權重。若未指定—weights參數,腳本會下載已發布模型進行評估。
模型推斷:
可通過如下命令進行模型推斷:
python infer.py --model-name=stnet--config=configs/stnet.txt --log-interval=1 --weights=$PATH_TO_WEIGHTS --filelist=$FILELIST
模型推斷結果存儲于STNET_infer_result中,通過pickle格式存儲。若未指定—weights參數,腳本會下載已發布模型進行推斷。模型精度:
當模型取如下參數時,在 Kinetics400數據集上的指標為:
參數取值

評估精度

來源:量子位